Author: timwi
Description:
BUG MIGRATED FROM SOURCEFORGE
http://sourceforge.net/tracker/index.php?func=detail&aid=855680&group_id=34373&atid=411192
Originally submitted by Nobody/Anonymous - nobody 2003-12-07 10:32
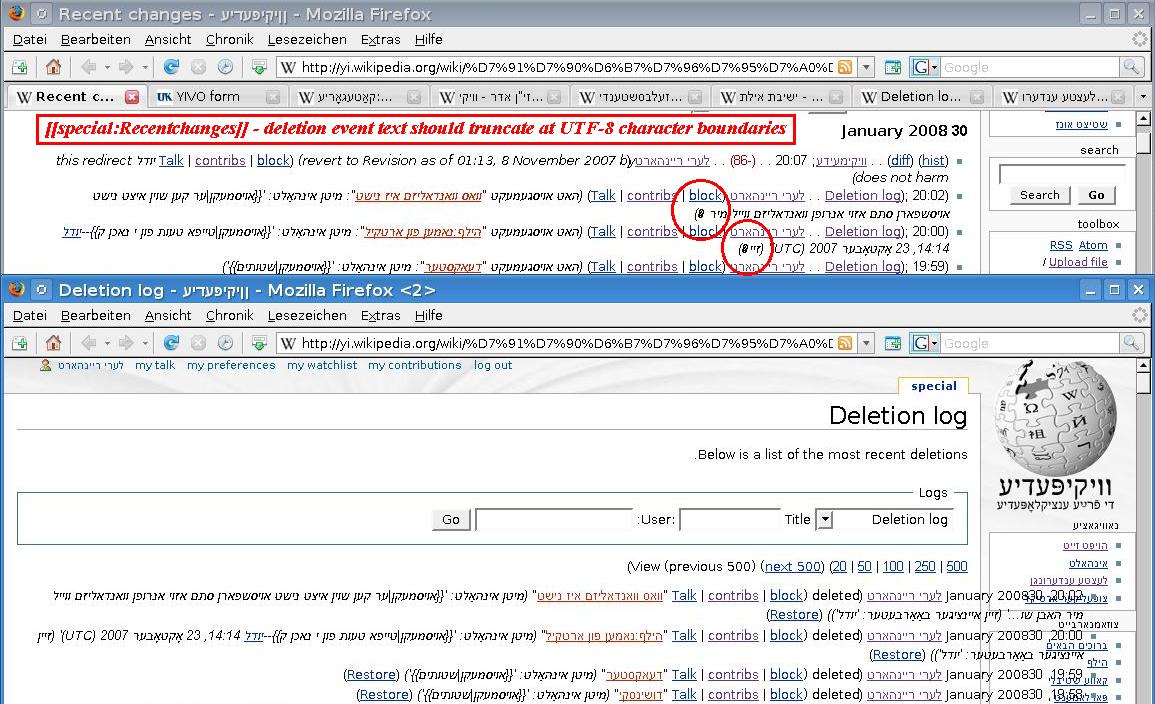
When someone write a long summary comment, it
messes RecentChanges, History, and other texts.
I think this is unique to languages using 2-byte
characters - when a character is cut-off in the middle, it
turns into some wierd character, and affects other part
of the page.
As an example, please see the following history page in
which the text (including the sidebar) is inappropriately
italicized.
http://ja.wikipedia.org/w/wiki.phtml?title=Wikipedia:%
E3%82%A6%E3%82%A3%E3%82%AD%E3%83%9A%E3%
83%87%E3%82%A3%E3%82%A2%E3%81%AE%E4%BB%
B2%E9%96%93&action=history
When this happens at RecentChanges, it is quite difficult
to read through it.
As a fix, it would be nice to automatically detect too
long summary comment and ask the user to shorten it.
Or there may be a way to properly cut 2byte-char texts.
That would be good, too.
Or maybe some other solution is available.
Thanks for the help,
Tomos ( wiki_tomos at hotmail dot com )
- Additional comments ------------------------
Date: 2003-12-07 11:31
Sender: SF user vibber
Confirmed; this seems to be a problem with how Internet
Explorer handles broken UTF-8 code; in at least some
circumstances it will eat the non-UTF-8-trail byte(s) that
follow the broken sequence. (I presume it's reading ahead
the entire number of bytes that the head byte specifies and
eating the false tail bytes instead of resynchronizing at
the break point. That's a real shame, since this ability is
one of the neatest things about UTF-8 compared with
traditional double-byte character sets.)
In the attached screenshot (from IE 6.0 on WinXP) this shows
it destroying the following ")" and even
the "<" that starts
the closing </em> tag, so the rest of the page is left in
italics when the markup is incorrectly interpreted.
Most other browsers I have tested (Mozilla, Camino, Safari)
replace only the broken sequence with a placeholder 'broken'
glyph, and correctly restart the UTF-8 interpretation at the
next byte, which as ASCII is itself a valid UTF-8 character
sequence. Konqueror 3.1.2 seems to break the following
")"
but not the "<", so the tags at least are intact.
Text gets cutoff at maximum lengths in a number of places;
titles as well as comments have a max size in the database,
which knows nothing of UTF-8 and treats our data as raw byte
strings. We should add a function to our code to perform a
UTF-8-safe max-byte-length string trimmer to keep the bad
ones out on general principle; since we can't fix IE from
choking on them we should also go through and eliminate any
remaining in the database.
Impact: mostly a cosmetic annoyance, but because of the
ability to damage markup in some popular browsers it could
harm usability. It's unlikely that cross-site scripting
attacks are possible through this, but it's bad juju anyway.
Database should be cleaned of any broken strings there are
now, and code should be fixed to avoid putting them in in
the future.
Only affects UTF-8 wikis, but that's a large and growing
portion of the user base (and we want to switch everything
to UTF-8 at some point). Asian languages are particularly
affected because UTF-8 balloons to 3 bytes per character in
most Asian scripts, so the byte limits are reached with a
smaller number of characters.
Version: unspecified
Severity: minor
OS: Windows XP