Author: itay_is_me
Description:
PDF and ODF files of bidi document, part of a Hebrew book from the Hebrew wikibooks
When trying to export bidi documents collection (download the collection), there are problems with both PDF and ODF files:
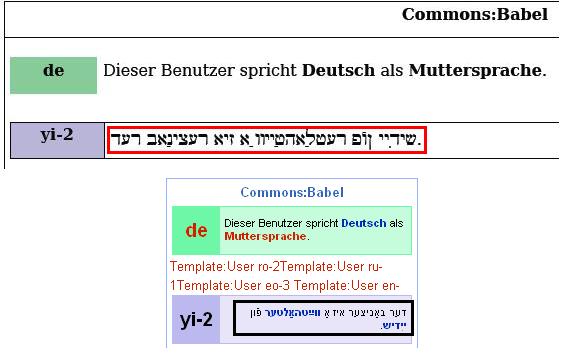
- Text in PDF files is mirrored (ordered from left to right instead of right to left). For example, instead of תכנות מתקדם, it is written םדקתמ תונכת.
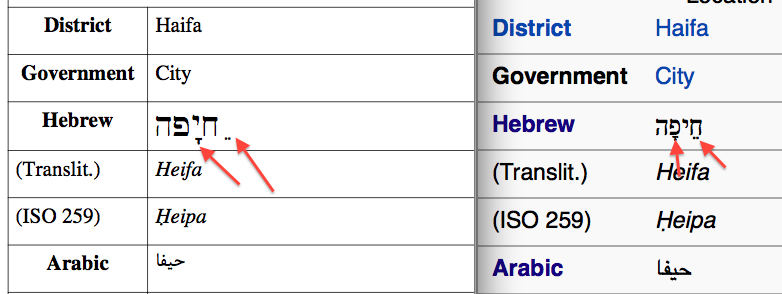
- Headers inside the document are displayed as blank squares (probably illegal font was used).
- ODF files are assigned as LTR document instead of RTL.
Version: unspecified
Severity: enhancement
OS: Windows NT
Platform: PC
Attached: