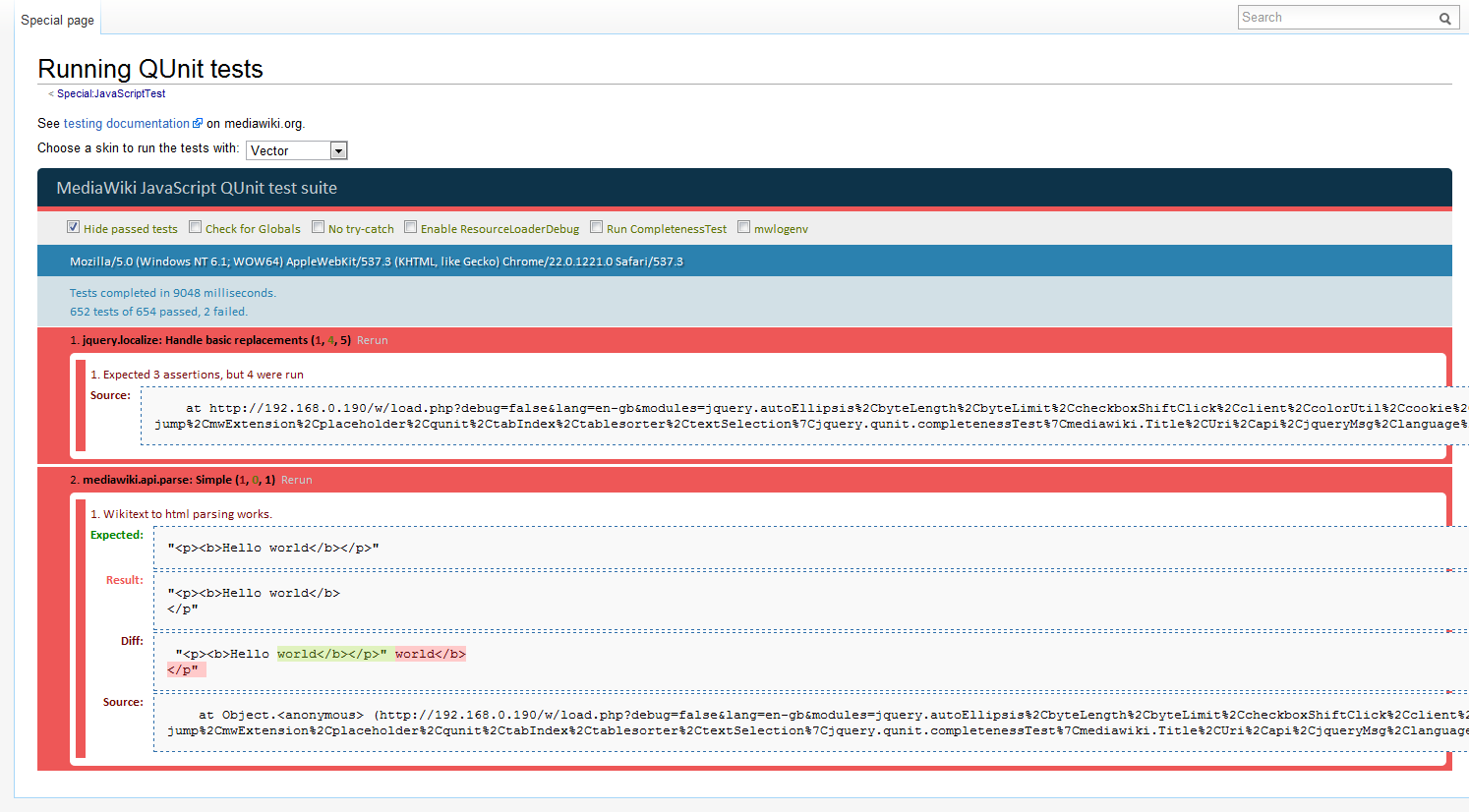
Or locally at least:
.
Expected:
"<p><b>Hello world</b></p>"
Result:
"<p><b>Hello world</b>
</p"
Diff:
"<p><b>Hello world</b></p>" world</b>
</p"
Version: 1.20.x
Severity: normal
| Reedy | |
| Aug 2 2012, 8:23 PM |
| F9803: mwapiparse.png | |
| Nov 22 2014, 12:53 AM |
Or locally at least:
.
Expected:
"<p><b>Hello world</b></p>"
Result:
"<p><b>Hello world</b>
</p"
Diff:
"<p><b>Hello world</b></p>" world</b>
</p"
Version: 1.20.x
Severity: normal
(In reply to comment #1)
This was already fixed a few days ago.
Has it not been submitted yet?
Yes it has, and it was merged. Tests are passing on current stable mediawiki/core master HEAD.
(In reply to comment #3)
Yes it has, and it was merged. Tests are passing on current stable
mediawiki/core master HEAD.
They're not on my dev wiki (hence opening this bug)...
diff --git a/tests/qunit/suites/resources/mediawiki.api/mediawiki.api.parse.test.js b/tests/qunit/suites/resources/mediawiki.api/mediawiki.api.parse.test.js
index 246b74a..f33edb0 100644 (file)
+++ b/tests/qunit/suites/resources/mediawiki.api/mediawiki.api.parse.test.js
@@ -9,7 +9,7 @@ QUnit.asyncTest( 'Simple', function ( assert ) {
api.parse( "'''Hello world'''" )
.done( function ( html ) {
// Html also contains "NewPP report", so only check the first part+ assert.equal( html.substr( 0, 25 ), '<p><b>Hello world</b></p>',
'Wikitext to html parsing works.' );
This unit test was failing for several weeks due to a non-js change (maybe someone changed the Parser and/or ApiParse?)
So then I fixed the unit test to no longer expect the line break between </b> and </p>. I always found it strange that it was inserted so this seemed like a fix.
Now you're saying it is back for you? It is passing for me (in Chrome).
Roan tested it on his machine and it is working there as well (he tested both the qunit test as well as accessing api.php?action=parse directly. In both cases there is no new line character inserted.
He also tested it on en.wikipedia.org, works there too.
So it turns out that it is failing/passing based on presence of Tidy.
Tidy removes the line-break that MediaWiki outputs between </b> and </p>.
I'll fix the test for now to parse the html and compare the dom instead of the html.