Author: lord_farin
Description:
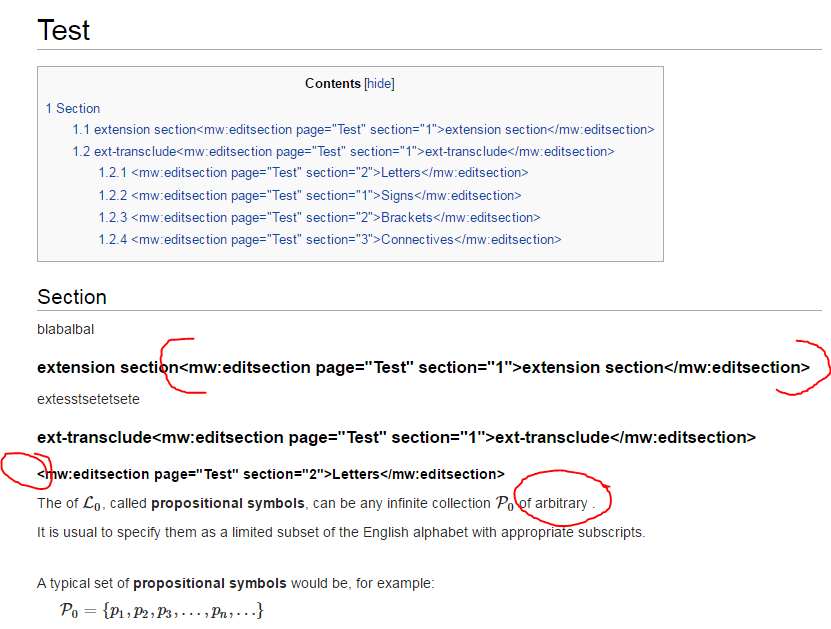
I have created an extension that uses a tag to generate new sections. This tag basically takes some parameters and displays as a section heading of the desired depth. The section content is listed as the inner HTML of the tag.
The problem that I am encountering is that the sections, so generated, do not show up in the table of contents (hereafter TOC).
Some relevant information is at http://www.mediawiki.org/wiki/Project:Support_desk#Sections_added_with_tag_extension_do_not_show_up_in_TOC_24342. A transcript:
"I have written a tag extension that allows for parameters to be given with a new section, which is processed by a section custom tag. I have dealt with the nesting issue bugzilla:1310 by implementing the suggested amendments to Preprocessor_DOM.php.
Everything works just fine, the sections are displayed with their correct header levels etc.etc.
There is just one problem. Namely, that the sections written using this section tag do not show up in the table of contents. Some var_dumps revealed to me that these headers do get their UNIQ modifiers. But apparently the TOC is incapable of taking these extra sections into account.
Please note that I am not looking for a solution that involves replacing the tag with a parser function; due to extensive presence of $\LaTeX$ the inability to use double closing braces anywhere is too crippling. Furthermore, entering whole sections as an argument to a parser function is obviously not a good and readable coding style.
Thank you for looking into this."
Version: 1.22.0