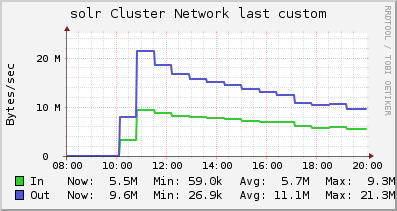
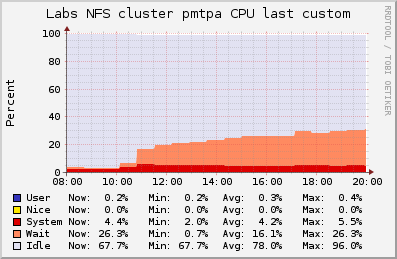
This morning we found out both beta and tools projects were "slow". The root cause is some jobs running on the solr project which exhaust the NFS server (labstore3) I/O operations.
The workaround is to reboot the instance solr-mw2.pmtpa.wmflabs to disable the stressing job as instructed by Nikolas Everett http://lists.wikimedia.org/pipermail/labs-l/2013-July/001381.html
The Solr experiment should be run on a different NFS system than the shared one. I guess a dedicated one.
Version: unspecified
Severity: normal