Parsoid is flooding the global job queue.
Version: wmf-deployment
Severity: normal
Whiteboard: [see comment 9]
| • MZMcBride | |
| Sep 20 2013, 10:37 PM |
| F11775: Screen_Shot_2013-09-30_at_3.01.54_PM.png | |
| Nov 22 2014, 2:06 AM |
| F11772: Screen_Shot_2013-09-21_at_12.01.25_PM.png | |
| Nov 22 2014, 2:06 AM |
Parsoid is flooding the global job queue.
Version: wmf-deployment
Severity: normal
Whiteboard: [see comment 9]
06.11 < TimStarling> mostly parsoid
06.11 < TimStarling> ParsoidCacheUpdateJob: 2413680 queued; 611 claimed (12 active, 599 abandoned)
For the record, my null editing respected maxlag. It also started August 28 and ended September 20.
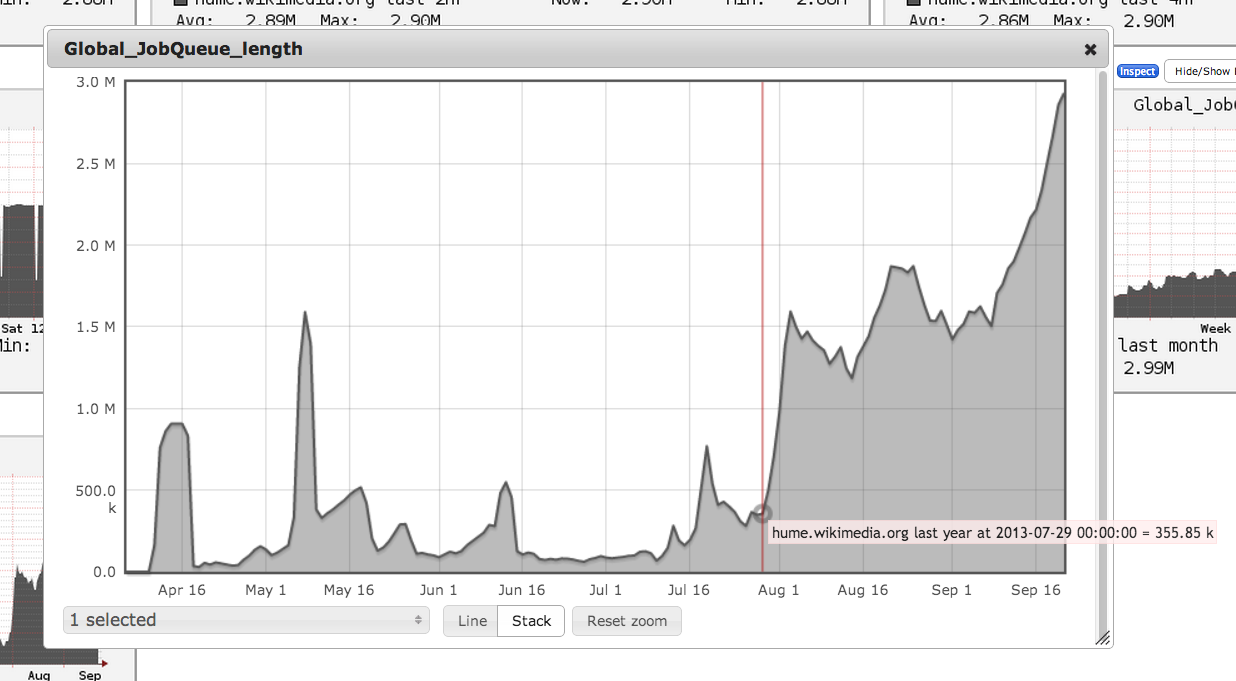
The graph goes wild around July 29, which seems to correspond tightly with "16:44 logmsgbot: catrope synchronized wmf-config/InitialiseSettings.php 'Enable VE for anons on es/fr/he/it/pl/ru/svwiki; set dewiki back to opt-in mode'".
We dequeue Parsoid jobs in a throttled manner to avoid overloading the API during edit spikes. This means that abnormal edit rates especially to templates can create a large backlog of jobs in the Parsoid queue. This is then slowly processed over time. Since this is a separate queue this won't hold up other job queues.
The main issue seems to be MZMcBride's null editing at a rate way beyond even bot edit limits. Do we have a product for DoS attack detection and -mitigation?
(In reply to comment #3)
The main issue seems to be MZMcBride's null editing at a rate way beyond even
bot edit limits.
Can you please clarify how, in your opinion, the null editing retroactively caused a spike a month before its beginning? Thanks.
(In reply to comment #2)
For the record, my null editing respected maxlag. It also started August 28
and
ended September 20.
maxlag has actually little relevance as a metric on the task you were doing...
(In reply to comment #3)
We dequeue Parsoid jobs in a throttled manner to avoid overloading the API
during edit spikes. This means that abnormal edit rates especially to
templates can create a large backlog of jobs in the Parsoid queue.
Where does Parsoid fit in to the general MediaWiki ecosystem? Are Parsoid jobs generated on every edit? If so, why? My understanding is that Parsoid is related to VisualEditor, so I have difficultly understanding how millions of Parsoid jobs would be queued unless they were all related to VisualEditor usage.
The main issue seems to be MZMcBride's null editing at a rate way beyond even
bot edit limits.
What's a bot edit limit?
Do we have a product for DoS attack detection and -mitigation?
DoS attack? I think it makes sense for all of us to focus on why and how Parsoid is flooding the global job queue. Suggesting anyone was performing a denial-of-service attack is both inappropriate and unhelpful. There are a number of anti-abuse measures built in to MediaWiki, to answer your question generally.
(In reply to comment #7)
Created attachment 13342 [details]
Screenshot to accompany comment 2
The spike around July 29 is easy to see and most likely corresponds with the deployment mentioned in comment 2. There are also spikes around August 14 and September 8, neither of which have been accounted for yet.
Attached:
(In reply to comment #6)
(In reply to comment #3)
We dequeue Parsoid jobs in a throttled manner to avoid overloading the API
during edit spikes. This means that abnormal edit rates especially to
templates can create a large backlog of jobs in the Parsoid queue.Where does Parsoid fit in to the general MediaWiki ecosystem? Are Parsoid
jobs
generated on every edit? If so, why?
After an edit, the Parsoid HTML for each affected article is generated / updated with jobs that perform HTTP requests to the Parsoid cluster. This ensures that requests from VisualEditor and other users are normally served straight from cache. We have been processing all edits from all Wikipedias since June. As expected, VE deployments have not made a noticeable difference to the load on the Parsoid cluster.
It seems that the Parsoid dequeue rate was slightly lower than the average enqueue rate since the end of July, which allowed the job backlog to build up a bit. During MZMcBride's null edit episode the backlog doubled in size. Since that stopped yesterday, the enwiki Parsoid job queue has drained by 10% (200k jobs).
So overall, the Parsoid job dequeue rate is slightly too low to absorb abnormal edit rates in a timely manner. It might be sufficient to slightly de-throttle the Parsoid dequeue rate while keeping an eye on the API cluster load (https://ganglia.wikimedia.org/latest/?r=hour&cs=&ce=&m=cpu_report&s=by+name&c=API+application+servers+eqiad&h=&host_regex=&max_graphs=0&tab=m&vn=&sh=1&z=small&hc=4).
(In reply to comment #9)
Since
that stopped yesterday, the enwiki Parsoid job queue has drained by 10% (200k
jobs).
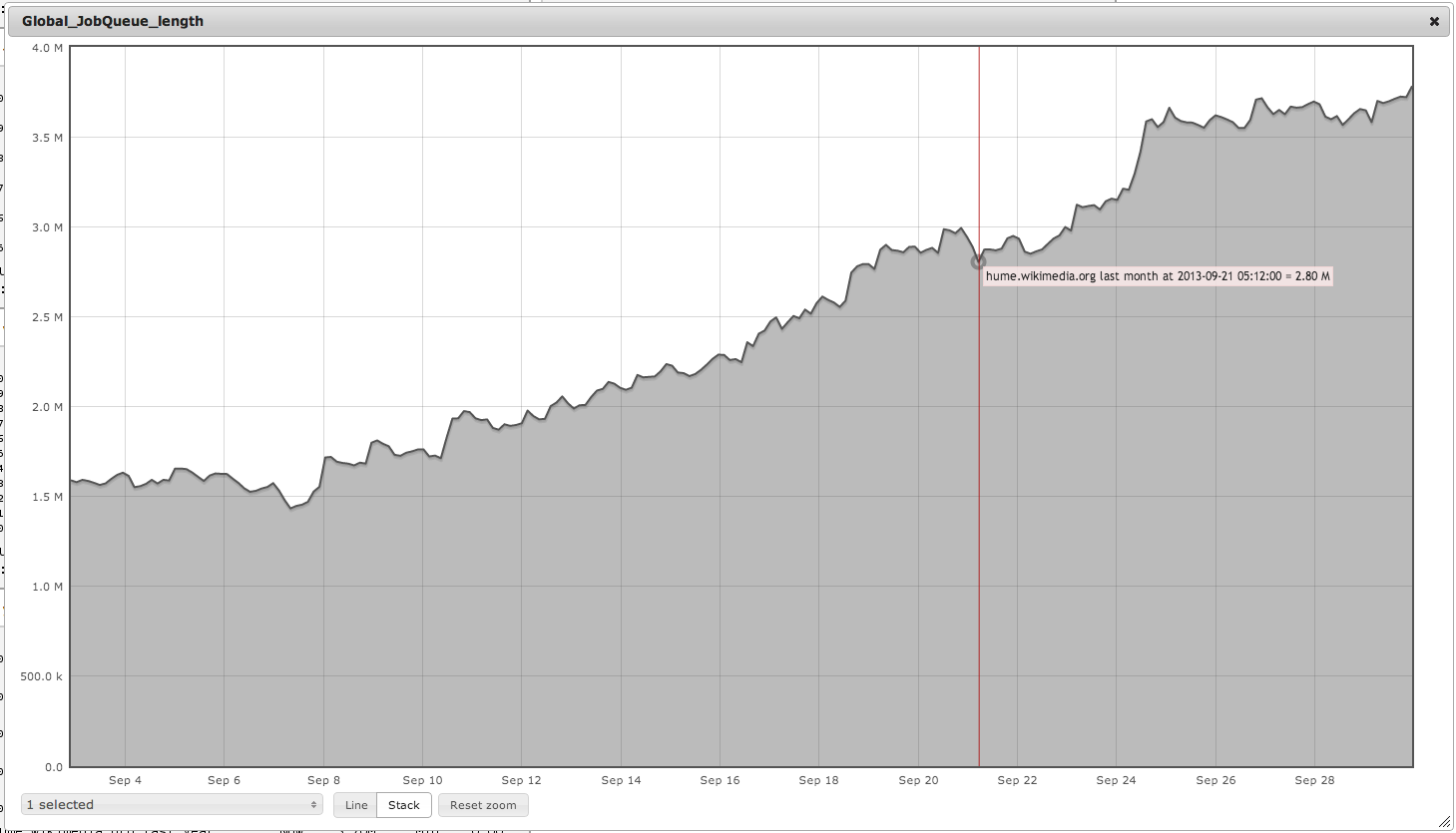
Did the other jobs increase then? The total job queue was 3.01M and is now 2.94M (it generally goes down in European nights and so).
(In reply to comment #9)
It seems that the Parsoid dequeue rate was slightly lower than the average
enqueue rate since the end of July, which allowed the job backlog to build
up a bit.
A bit? Looking at https://ganglia.wikimedia.org/latest/graph_all_periods.php?c=Miscellaneous%20pmtpa&h=hume.wikimedia.org&v=823574&m=Global_JobQueue_length&r=hour&z=default&jr=&js=&st=1365625056&z=large it seems like the queue went from 355,850 to 1,590,000 in the span of about six days (from July 29 to August 3). It grew by... 346%? That's what you're calling "a bit"?
(In reply to comment #10)
(In reply to comment #9)
Since
that stopped yesterday, the enwiki Parsoid job queue has drained by 10% (200k
jobs).Did the other jobs increase then?
Jobs in other job queues (I see 26k refreshlinks2 jobs on enwiki for example), and/or Parsoid jobs on other wikis have likely slightly increased in number. Overall the queue size has slightly decreased since the null-editing was stopped.
Changed the subject to be more accurate. Some more clarification for those less familiar with the way Parsoid caching works:
So in the bigger picture this is annoying, but not critical.
Still, to avoid any misunderstandings: Null editing at rates way higher than those allowed for bots is at best a very bad idea.
(In reply to comment #13)
Still, to avoid any misunderstandings: Null editing at rates way higher than
those allowed for bots is at best a very bad idea.
Bots are explicitly not rate-limited.
I still see no answer about what the spike on July 29 was: are you saying it wasn't about parsoid, but just a coincidence? Or that it was normal to queue over a million jobs in a couple of days (initial caching of all pages or something?) but the second million was too much?
The new summary seems incorrect in two ways:
What's sure is that we no longer seem to have any meaningful job queue data.
(In reply to comment #14)
Bots are explicitly not rate-limited.
https://en.wikipedia.org/wiki/Wikipedia:Bot_policy#Bot_requirements states that "bots doing non-urgent tasks may edit approximately once every ten seconds".
Am I missing something?
(In reply to comment #16)
(In reply to comment #14)
Bots are explicitly not rate-limited.
https://en.wikipedia.org/wiki/Wikipedia:Bot_policy#Bot_requirements states
that
"bots doing non-urgent tasks may edit approximately once every ten seconds".
Am I missing something?
That requirement is imposed by the community, it is not necessarily a technical limit. If you look at https://en.wikipedia.org/wiki/Special:ListGroupRights, the 'bot' group is deliberately exempted from rate limits with the 'noratelimit' userright.
No user in the "bot" user group was used to null edit. Just a standard and unprivileged (albeit autoconfirmed) account.
On Wikimedia wikis, 'edit' is rate-limited only for 'ip' and 'newbie', but not for 'user' or 'bot' or any other group, as far as I can tell.
(In reply to comment #15)
I still see no answer about what the spike on July 29 was: are you saying it
wasn't about parsoid, but just a coincidence? Or that it was normal to queue
over a million jobs in a couple of days (initial caching of all pages or
something?) but the second million was too much?
Just editing a handful really popular templates (some are used in >7 million articles) can enqueue a lot of jobs (10 titles per job, so ~700k jobs). As can editing content at high rates. Core happens to cap the number of titles to re-render at 200k, while Parsoid re-renders all, albeit with a delay.
Ideally we'd prioritize direct edits over template updates as only the former has any performance impact. Editing a page with slightly out-of-date template rendering will still yield correct results. Longer-term our goal is to reduce API requests further so that we can run the Parsoid cluster at capacity without taking out the API.
And yes, I was referring to very straightforward social rules that are designed to prevent our users from overloading the site with expensive operations. We currently provide powerful API access that can easily be abused. If the attitude that everything that is not technically blocked must surely be ok becomes more popular we'll have to neuter those APIs significantly. Maybe it is actually time to technically enforce social rules more strictly, for example by automatically blocking abusers.
I'm not sure how familiar you are with the actual writing and enacting of those social rules, but surely here nothing was done against them. The social rules in the various variations of the global [[m:Bot policy]] are not about performance; the speed limit is typically driven by users not wanting their Special:RecentChanges and Special:WatchList to be flooded, which in this case obviously didn't happen (so let's not even start debating what's an "edit").
Besides, I don't really have an answer yet to my question, though we're getting nearer; probably it would be faster if we avoided off-topic discussions on alleged abuse and similar stuff.
(In reply to comment #19)
(In reply to comment #15)
I still see no answer about what the spike on July 29 was: are you saying it
wasn't about parsoid, but just a coincidence? Or that it was normal to queue
over a million jobs in a couple of days (initial caching of all pages or
something?) but the second million was too much?Just editing a handful really popular templates (some are used in >7 million
articles) can enqueue a lot of jobs (10 titles per job, so ~700k jobs). As
can
editing content at high rates. Core happens to cap the number of titles to
re-render at 200k, while Parsoid re-renders all, albeit with a delay.
Thanks, so I guess the answer is the second. Can you then explain why "the second million was too much", i.e. why reaching 2M job queue is in your opinion all fine and normal while 3 is something absolutely horrible and criminal? Thanks.
(In reply to comment #20)
Can you then explain why "the
second million was too much", i.e. why reaching 2M job queue is in your
opinion
all fine and normal while 3 is something absolutely horrible and criminal?
Thanks.
Popular templates are protected for a reason, and editors don't edit them needlessly, as they know about the high load this causes.
For templates there is no way around the load this creates when they really need to be edited. I have a hard time seeing a similarly good reason for making 8 million null edits at a rate of ~4/second. Especially without talking to the people responsible for keeping the site running and in contravention of the bot policy.
(In reply to comment #21)
Popular templates are protected for a reason, and editors don't edit them
needlessly, as they know about the high load this causes.For templates there is no way around the load this creates when they really
need to be edited.
Ok, so people avoid things which cause overload but still in July we had about 2M additional job queue items. And it seems that's fine. What's not fine then, what is this bug about? Can we please identify the problem and the source of it? Otherwise I don't see how one can identify solutions.
I have a hard time seeing a similarly good reason for
making
8 million null edits at a rate of ~4/second.
I'm having a hard time too. They are just speculations without answers to what above.
Especially without talking to
the
people responsible for keeping the site running
(This makes sense.)
and in contravention of the
bot
policy.
Sigh. There isn't any contravention of the bot policy. The relevant local page is [[Wikipedia:Don't worry about performance]].
Hint: the policies or pseudo-policies you are looking for are on wikitech, e.g. [[wikitech:Robot policy]]. I don't remember which one precisely but there is one written by Tim which explicitly says "if you're causing problems/bringing the site down we'll block you", period.
In this case however, I still don't see what the problem is. Again, why is 2M not a problem but 3M yes?
(In reply to comment #23)
Just curious - is there anything actionable that can possibly come out of
this
bug?
Yes! I'm hoping for a definition of "what is the problem" to actually come out of it. It may take a hundred more comments though, given the current speed we're approaching it at.
(In reply to comment #24)
Yes! I'm hoping for a definition of "what is the problem" to actually come
out
of it. It may take a hundred more comments though, given the current speed
we're approaching it at.
May I suggest using something that's not bugzilla for that purpose? I understand the need for clarity, but honestly a bugzilla ticket is probably not the best way to do it. A mailing list post, perhaps?
@Yuvi: For the technical part, see comment #9. The social / DoS prevention issue is probably better discussed elsewhere.
(In reply to comment #23)
Just curious - is there anything actionable that can possibly come out of
this bug?
This bug was filed under the assumption that job queues shouldn't contain millions of jobs.
Gabriel seems to suggest throughout this bug report that the global job queue size is irrelevant (or rather, that he's apparently unconcerned with its size), so I'm not sure there is anything actionable here. This may be a wontfix.
(In reply to comment #21)
For templates there is no way around the load this creates when they really
need to be edited. I have a hard time seeing a similarly good reason for
making 8 million null edits at a rate of ~4/second.
There are a lot of pages to edit. If we edited one page per minute and edited 31,000,000 pages, that would take approximately 58.9 years. Obviously we're going to have to go a bit faster than that.
Many pages have not been re-parsed or purged from cache in years (since 2005 for the oldest pages). This results in outdated or incorrect *links entries, stale HTML cache, etc., in addition to a number of lurking page text anomalies (incorrectly unsubstituted templates, incorrectly unexpanded user signatures, etc.). Null editing is built in to MediaWiki to address these issues on a per-page basis. You've yet to identify any issue with using this built-in feature.
Other than a global job queue that's already flooded, were there any issues from null editing that you (Gabriel) or anyone else has found? If so, I'd like to learn more so that I can understand and grow as a contributor.
(In reply to comment #3)
The main issue seems to be MZMcBride's null editing at a rate way beyond even
bot edit limits.
It's difficult to look at these claims as being anything other than spurious. Attachment 13412 shows a continued increase in the global job queue (now exceeding 3.78 million jobs).
I'm restoring the original bug summary, which was most accurate: Parsoid is flooding the global job queue. Nobody seems to be particularly concerned with this, however, so it may make sense to mark this bug as resolved/worksforme.
@MZMcBride: I think both the broader technical and the social issue have been discussed sufficiently now. From now on I am not going to discuss anything but the Parsoid job queue length in this bug. Please discuss other aspects elsewhere.
PS: There is no such thing as a global job queue. There are several independent queues which are stored on the same infrastructure and graphed as an aggregate.
Change 86745 had a related patch set uploaded by GWicke:
Bug 54406: Speed up Parsoid job processing
(In reply to comment #30)
@MZMcBride: I think both the broader technical and the social issue have been
discussed sufficiently now. From now on I am not going to discuss anything
but the Parsoid job queue length in this bug.
I was repeatedly called out (by you and others) on this bug for causing the increased job queue length when there's no evidence this was the case.
(In reply to comment #32)
(I'm removing myself from cc as we don't even manage to get a fact-based
summary.)
I wish I could remove myself, but Bugzilla doesn't allow the reporter to be changed. :-(
(In reply to James Forrester from comment #36)
Can we close this bug now? I believe this has been fixed.
No feedback => Closing.