(happened on wed 9th of July)
- check with gage whether this work already took place
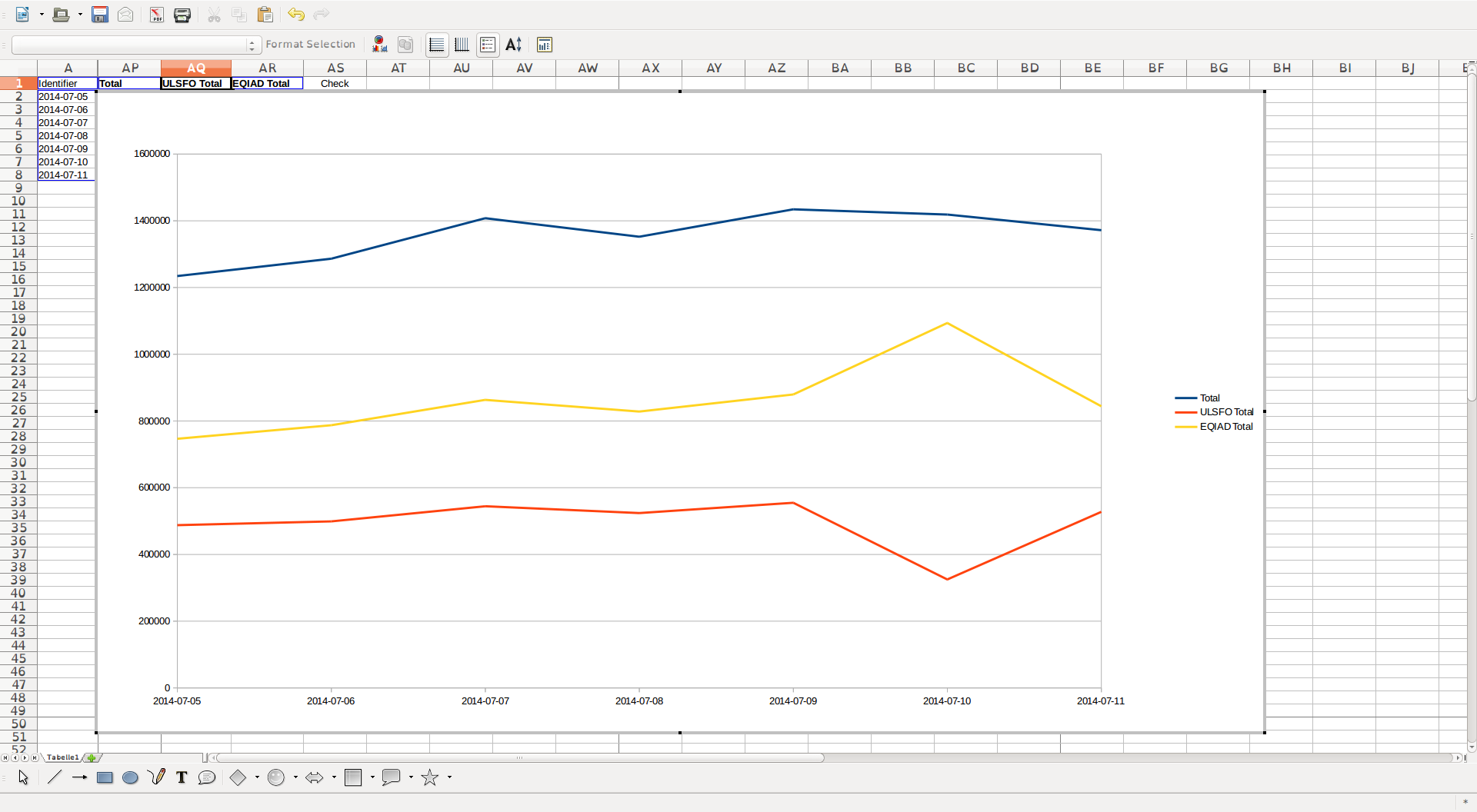
- check that during the switchover, hosts were correctly reporting
- like only the correct hosts going down during the migration
- the other hosts were picking up the correct traffic
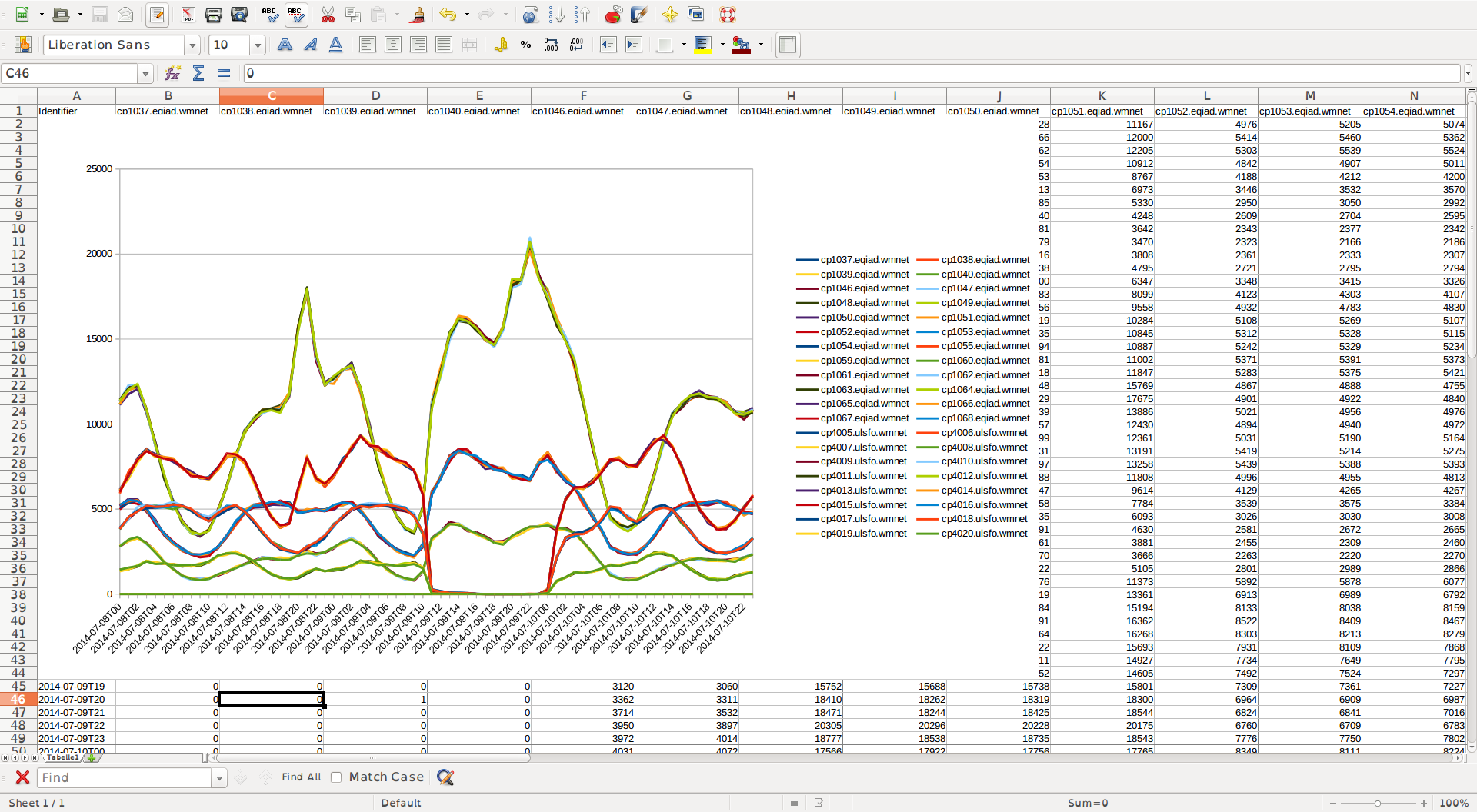
- check that each host is still reporting the expected number of requests
- sampled-1000 logs (stat1002 /a/squid/...)
- mobile-sampled-100 logs (stat1002 /a/squid/...) can be done by plotting requests per host per time
- zero logs (stat1002 /a/squid/...)
- edit logs (stat1002 /a/squid/...)
- Find out where those files get written, and find a way to cover
- oxygen,
- gadolinium (unicast)
- gadolinium (multicast)
- erbium if they are not covered by the above file
Version: unspecified
Severity: normal
Whiteboard: u=Kevin c=General/Unknown p=0 s=2014-07-24