Rummana saw the issue described in bug 70103 again.
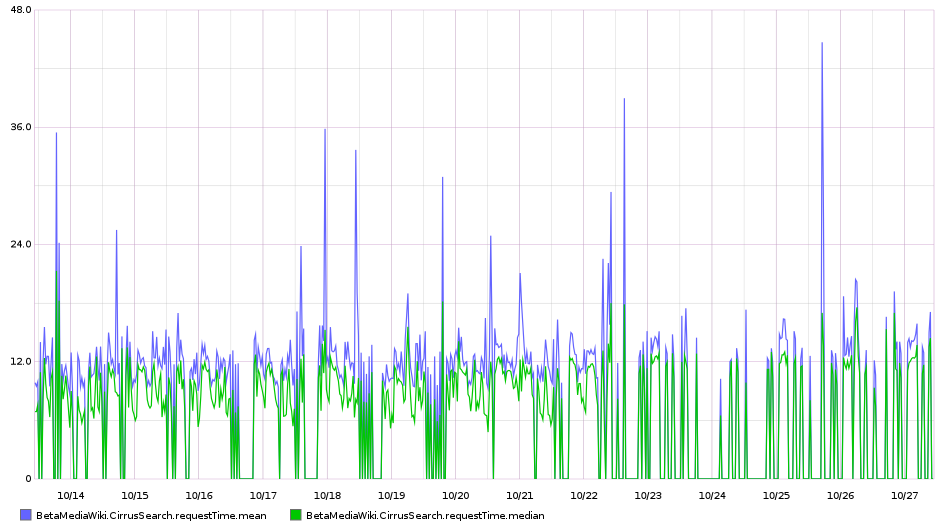
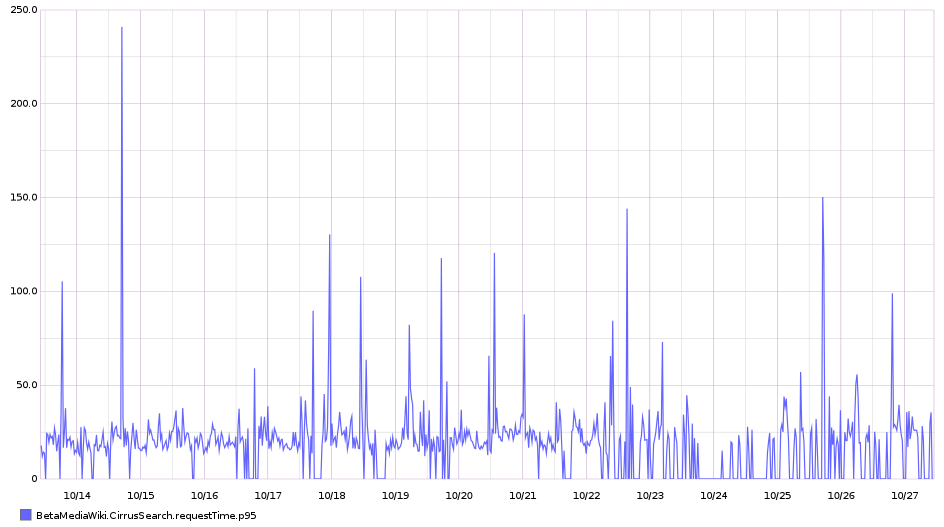
The search requests (either in the drop down on the top right, or within VE) are sometimes taking a lot longer than normal.
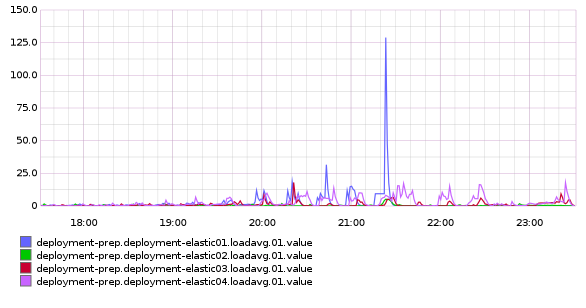
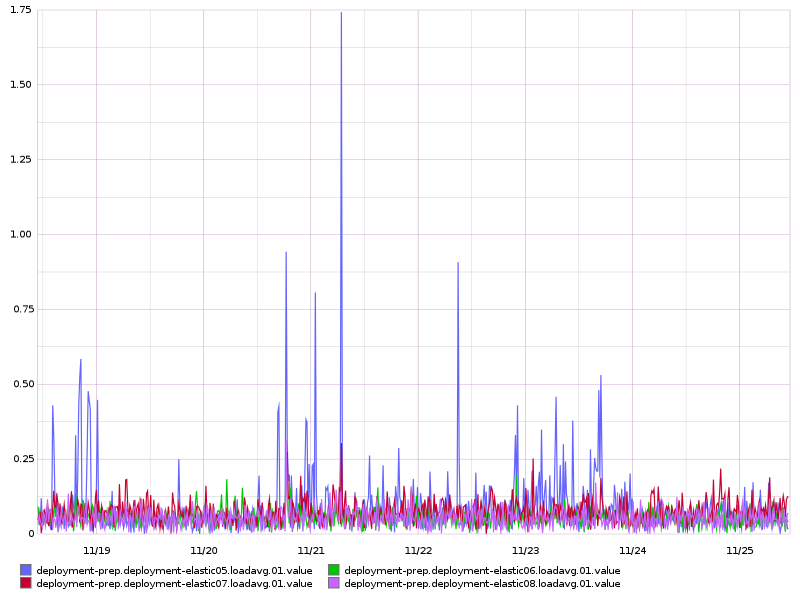
Looking at graphite I see a weird spike on one of the elastic search boxes: 1 minute load averages on deployment-elastic* instances over 7 days
Version: unspecified
Severity: normal
See Also:
https://bugzilla.wikimedia.org/show_bug.cgi?id=70940